课题简介
生成网路是近年来深度学习领域研究比较火热的方向,它使得计算机具有如同人一般的创造力,在诸多领域都具有巨大的应用前景。前些年风靡全球的换脸带给了我们一些启迪,我们希望通过融合不同领域的生成技术,实现视频的完全生成,即不仅换脸,我们还要换身体、换声音,将一段输入的视频转变成另一段视频里的表现而不改变自己本身模样。
参考论文
视频转换:《Everybody dance now》 音频转换:《CycleGAN-VC2: Improved CycleGAN-based Non-parallel Voice Conversion》
实现方法
一.音频转换
1. 音频特征提取
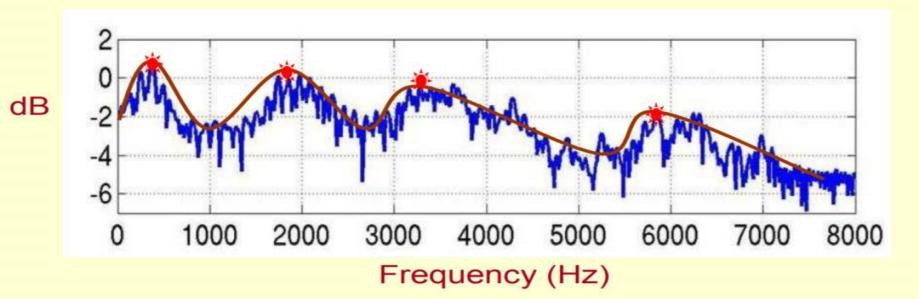
由于一段语音的音频特征主要有基频、频谱包络和非周期性参数这三种,对于这三种信息可以用相关音频特征提取算法进行提取。
2.模型训练
 此处使用CycleGAN模型,CycleGAN在最开始提出时,是应用在图片的风格迁移领域,可以解决数据的不对称问题,这正好与音频转换的目标相似,即对于非平行的语音数据进行语音上的“风格迁移”,应用于本项目的CycleGAN的生成器如图的左半部分所示,鉴别器如图的右半部分所示。
在损失函数的选择上,生成器的损失函数主要是Adversarial loss(式1)、Cycle-consistency loss(式2)和identity-mapping loss(式3)
此处使用CycleGAN模型,CycleGAN在最开始提出时,是应用在图片的风格迁移领域,可以解决数据的不对称问题,这正好与音频转换的目标相似,即对于非平行的语音数据进行语音上的“风格迁移”,应用于本项目的CycleGAN的生成器如图的左半部分所示,鉴别器如图的右半部分所示。
在损失函数的选择上,生成器的损失函数主要是Adversarial loss(式1)、Cycle-consistency loss(式2)和identity-mapping loss(式3)
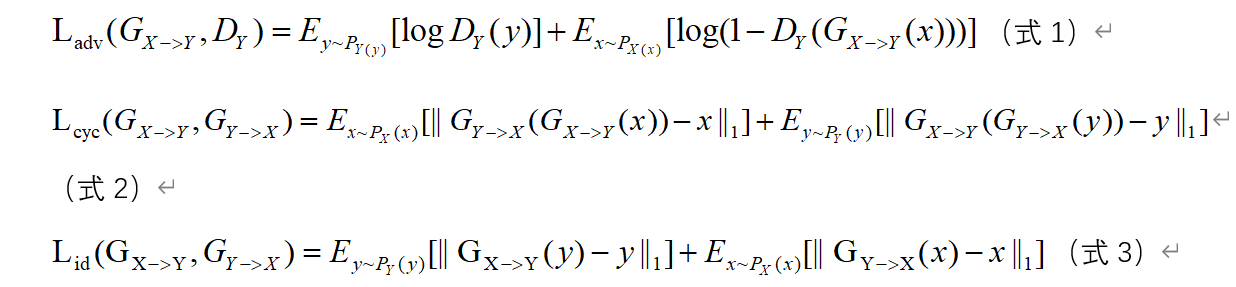 鉴别器的损失函数为Adversarial loss(即CycleGAN 针对鉴别器的对抗损失函数)和Adversarial 2 loss(式4)(加入此损失后效果得到明显的提升)。
鉴别器的损失函数为Adversarial loss(即CycleGAN 针对鉴别器的对抗损失函数)和Adversarial 2 loss(式4)(加入此损失后效果得到明显的提升)。
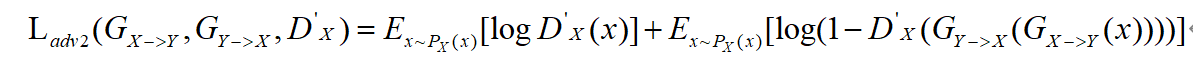 (式4)
(式4)
3.语音合成
得到了转换后的基频、频谱包络和非周期性参数之后,通过语音合成器进行新的语音的合成,就可以得到一段新的语音。
二.视频转换
1.总体流程
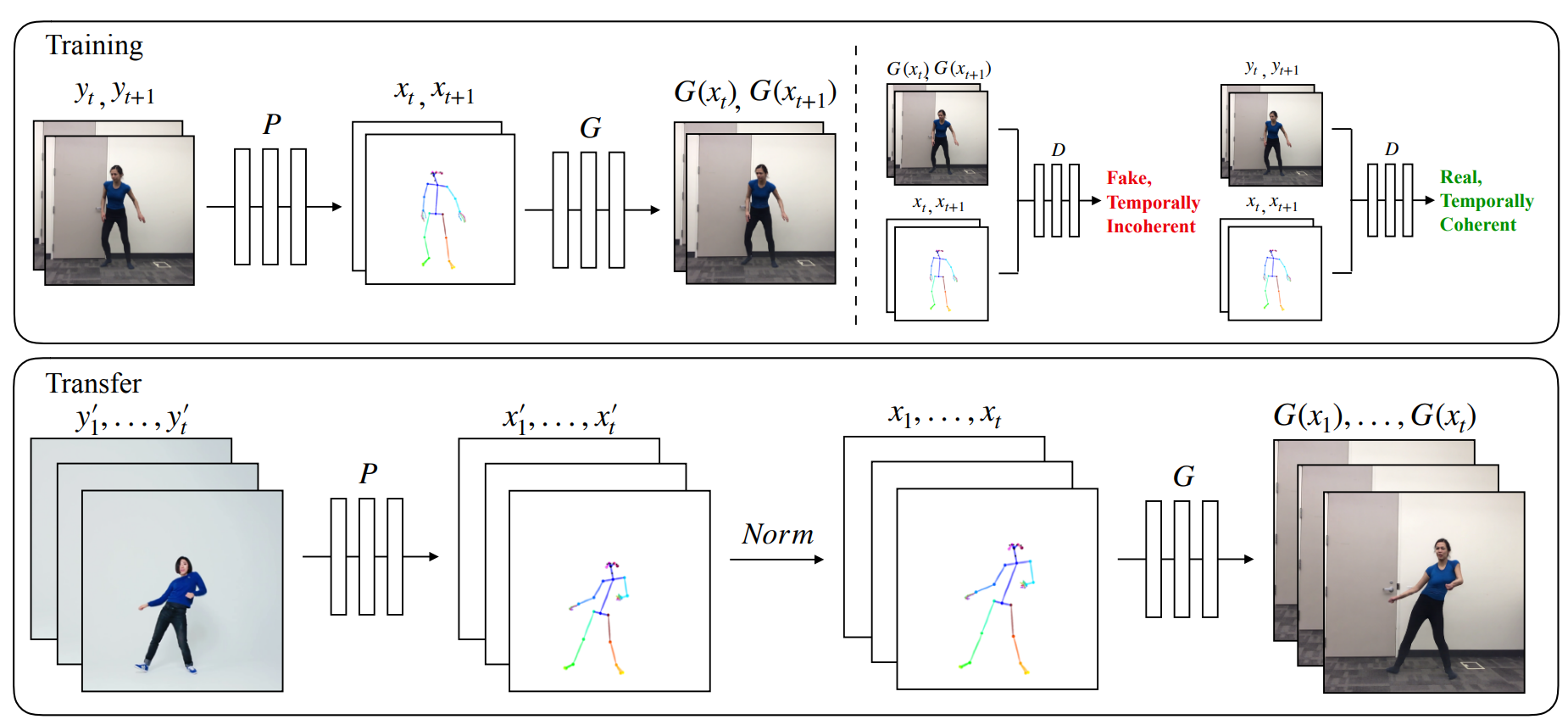 视频转换部分的总体流程如图所示,Training部分训练目标视频的对抗生成网络,将目标视频逐帧分解后,将图片传入姿态识别网络P中,生成对应的姿势棒图,再将姿势棒图输入到生成器G中,生成虚假的照片,将真实照片与姿势棒图、虚假照片与姿势棒图传入判别器D中判断照片的真实性,最终训练完成后取生成器G作为目标视频的生成器。Transfer部分为原视频迁移,将原视频逐帧分解后,将图片传入姿态识别网络P中,生成对应的姿势棒图,再将姿势棒图根据目标视频的尺寸、大小等进行归一化Norm,将归一化的照片传入训练好的生成器G中生成相同动作的虚假照片,将每一帧的虚假照片合成为视频即得到最终的生成视频。
视频转换部分的总体流程如图所示,Training部分训练目标视频的对抗生成网络,将目标视频逐帧分解后,将图片传入姿态识别网络P中,生成对应的姿势棒图,再将姿势棒图输入到生成器G中,生成虚假的照片,将真实照片与姿势棒图、虚假照片与姿势棒图传入判别器D中判断照片的真实性,最终训练完成后取生成器G作为目标视频的生成器。Transfer部分为原视频迁移,将原视频逐帧分解后,将图片传入姿态识别网络P中,生成对应的姿势棒图,再将姿势棒图根据目标视频的尺寸、大小等进行归一化Norm,将归一化的照片传入训练好的生成器G中生成相同动作的虚假照片,将每一帧的虚假照片合成为视频即得到最终的生成视频。
2.人体姿态估计
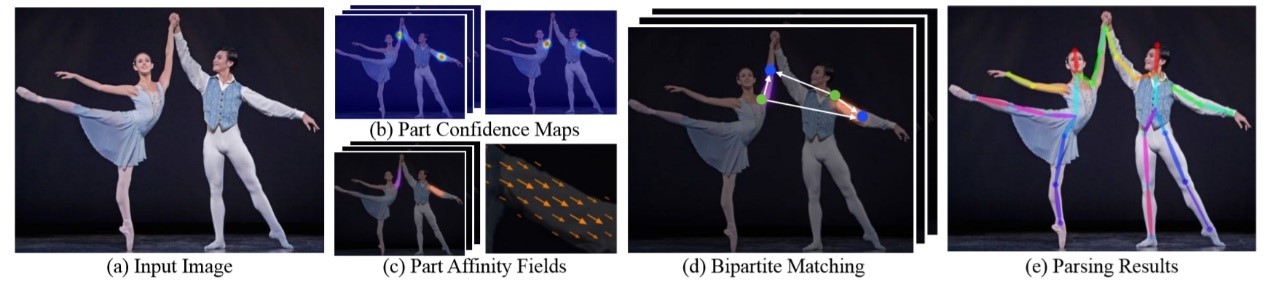 本项目中的姿态识别网络P采取《Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields》,如图所示是网络的pipeline,首先根据输入图片(a)生成一个Part Confidence Maps(b)和一个Part Affinity Fields(c):前者就是heatmap,用来预测关键点的位置;后者是一个主要创新点—PAF,PAF实际上是在关键点之间建立的一个向量场,描述一个limb的方向。有了heatmap和PAF,使用二分图最大权匹配算法来对关键点进行组装(d),从而得到人体骨架(e)
本项目中的姿态识别网络P采取《Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields》,如图所示是网络的pipeline,首先根据输入图片(a)生成一个Part Confidence Maps(b)和一个Part Affinity Fields(c):前者就是heatmap,用来预测关键点的位置;后者是一个主要创新点—PAF,PAF实际上是在关键点之间建立的一个向量场,描述一个limb的方向。有了heatmap和PAF,使用二分图最大权匹配算法来对关键点进行组装(d),从而得到人体骨架(e)
3.图片生成
 本项目采用Pix2Pix网络,若算力有限可以使用Pix2Pix网络,想要提升画面质量使用Pix2PixHD网络(提升效果显著)。
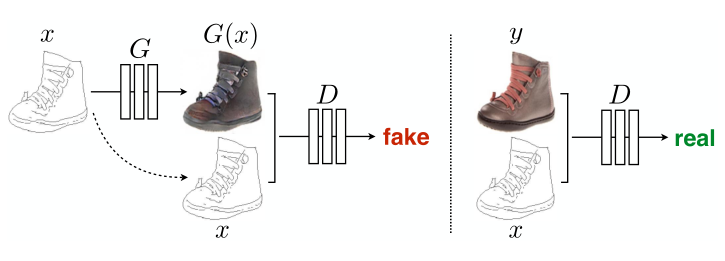
pix2pix网络结构如图所示,生成器G是Unet结构,输入的轮廓图 编码再解码成真是图片,判别器D用到的是条件判别器PatchGAN,判别器D的作用是在轮廓图 的条件下,对于生成的图片 判断为假,对于真实判断为真。
本项目采用Pix2Pix网络,若算力有限可以使用Pix2Pix网络,想要提升画面质量使用Pix2PixHD网络(提升效果显著)。
pix2pix网络结构如图所示,生成器G是Unet结构,输入的轮廓图 编码再解码成真是图片,判别器D用到的是条件判别器PatchGAN,判别器D的作用是在轮廓图 的条件下,对于生成的图片 判断为假,对于真实判断为真。
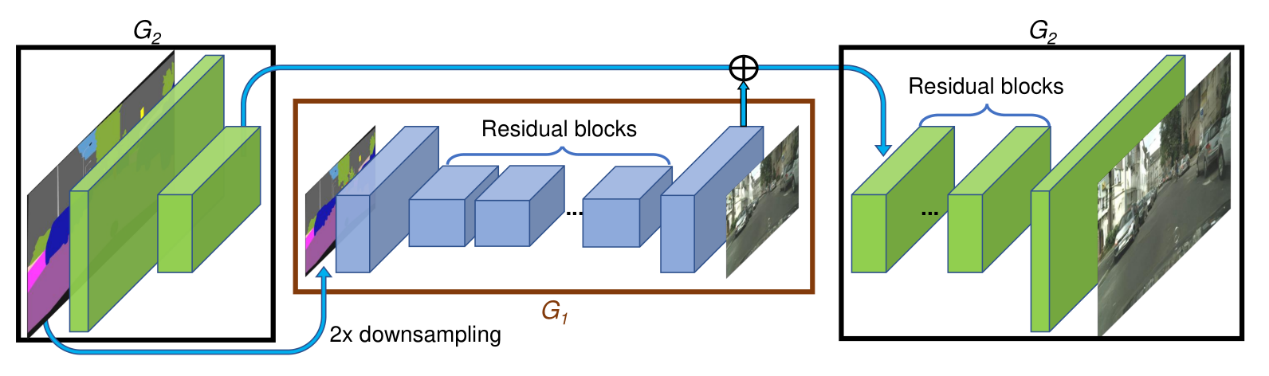
Pix2PixHD模型结构如图所示,生成器由两部分组成,G1和G2,其中G2又被割裂成两个部分。G1和pix2pix的生成器没有差别,就是一个end2end的U-Net结构,G2的左半部分提取特征,并和G1的输出层的前一层特征进行相加融合信息,把融合后的信息送入G2的后半部分输出高分辨率图像。判别器使用多尺度判别器,在三个不同的尺度上进行判别并对结果取平均。判别的三个尺度为:原图,原图的1/2降采样,原图的1/4降采样(实际做法为在不同尺度的特征图上进行判别,而非对原图进行降采样)。
4.姿态归一化
在姿态归一化上,通过姿势棒图中脚踝的位置标定任务位置,利用下述公式对原视频与目标视频的姿势棒图进行归一化。由于原论文中的归一化依赖于脚踝位置的识别,所以在脚踝未被识别的状况下(如遮挡等)归一化算法会失效,于是项目改进了原论文的方法,采取多层次的归一,以脚踝、鼻子与躯干三个关键点进行归一,避免了脚踝关键点失效造成的归一化失效问题。
5. 生成视频
将原视频归一化后的姿势棒图输入到训练好的生成网络中,即可获得每一帧的生成图像,将生成图像合成就得到了完整的生成视频。